
Most data trainings are focused on computer-based tools. Excel tutorials, Tableau trainings, database intros – these all talk about working with data as a question of learning the right technology. I’m here to argue against that. Building your capacity to work with data can be done without becoming a “magician” in some software tool.
Data literacy is not the same as computer literacy. This is an important distinction, because there are lots of people that are intimidated by computer technologies; but many of them are otherwise ready and excited to work with data. In my workshops with non-profits I find that this technological focus excludes far too many people. Defining data literacy in technological terms doesn’t welcome those people to learn.
To support this argument, let me start by describing what I mean by the skills needed to work with data. In my workshops we focuses on:
- Asking good questions
- Acquiring the right data to work with
- Finding the data story you want to tell
- Picking the right technique to tell that story
- Trying it out to see if your audience understands your story
With Catherine D’Ignazio, I’ve been creating hands-on, participatory, arts-based activities to support each of these. Some involve simple web-based tools, but none are about mastering those tools as the skill to learn. They treat the technology as a one-button means to an end. The activity is designed to work the muscle.
Curious about how those work? If you want to learn how to start working with a set of data to ask good questions, use our WTFcsv activity. Struggling to learn about the types of stories you can find in data? Try our data sculptures activity to quickly build some mental scaffolding you can use.
Those are two quick examples. Here’s a sketch of all the activities we are building out and how they fit into the process I just described:
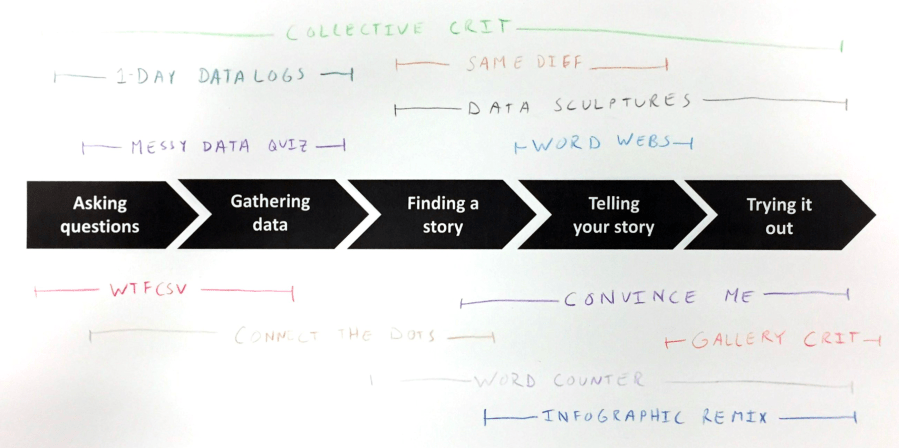
Some of these are old, and well documented on DataBasic.io; others are new and lightly sketched out on my Data Therapy Activities page; the rest are still nascent. We’re trying to build a road for many more people to learn to “speak” data, before they even touch tools like Excel or Tableau. These activities support this alternate entry point to data literacy; one that is fun and engaging to everyone!
Don’t get me wrong – there is certainly a place for learning how to use these amazing software tools. My point is that technology isn’t the only way to build data literacy.
You don’t need to be a computer whiz to work with data; you can exercise the muscles required with hands-on arts-based activities. We’re trying to build and document an evidence base demonstrating how the muscles you develop for working with data outside of computers easily transfer to computer based tools. Stay tuned for future blog posts that summarize that evidence…






You must be logged in to post a comment.